
In diesem Artikel behandeln wir das Thema Duplicate Content und die Notwendigkeit, ihn zu vermeiden. Duplicate Content (= doppelter Inhalt) beeinträchtigt das Vertrauen der Suchmaschinen und hat negative Auswirkungen auf das Ranking, den Traffic und das Nutzererlebnis. Wir zeigen Ihnen verschiedene Strategien zur Vermeidung von Duplicate Content, darunter Onpage-Optimierungstechniken wie Canonical Tags und URL-Struktur sowie inhaltliche Maßnahmen und technische Ansätze.
Bedeutung von Unique Content
Google und Co. bewerten Websites nach der Qualität und Relevanz ihrer Inhalte. Originelle Inhalte gelten als wertvoll und erhalten eine höhere Priorität bei der Platzierung in den Suchergebnissen. Doch was bedeutet originell? Wichtig sind einzigartige Informationen und ein echter Mehrwert für die Nutzer:innen. Diese bleiben bei interessanten und wissenswerten Fakten länger auf der Seite, teilen den Artikel oder interagieren in irgendeiner Form mit Buttons, Links etc. Verweildauer und Interaction-Rate sind wichtige SEO-Faktoren. Auch die Bounce-Rate, also die Absprungrate verringert sich dadurch. Ein hilfreicher Tipp hier sind Visualisierungen, also Grafiken der von Ihnen angegebenen Daten.
Der Begriff Duplicate Content dagegen bezieht sich auf die Existenz von identischen oder nahezu identischen Inhalten auf verschiedenen URLs oder Domains. Gleiche oder sehr ähnliche Texte, Bilder, Videos oder andere Inhalte sind dann an verschiedenen Stellen im Internet veröffentlicht. Duplicate Content kann sowohl intern innerhalb einer Website als auch extern auf verschiedenen Websites auftreten. Dies kann beabsichtigt oder unbeabsichtigt und sowohl manuell als auch automatisch erzeugt worden sein.
Negative Auswirkungen auf SEO und Ranking
Keyword-Konkurrenz entsteht, wenn mehrere Websites mit identischem Inhalt um die Aufmerksamkeit für relevante Keywords und Suchbegriffe konkurrieren. In diesem Szenario muss die Suchmaschine entscheiden, welche Website den besten Inhalt für eine bestimmte Suchanfrage liefert. Hier spielen viele verschiedene Faktoren mit rein, sowohl redaktionell als auch technisch.
Wie reagieren Sie, wenn Sie auf einer Website die gesuchten Informationen nicht finden oder den Eindruck gewinnen, dass sich Inhalte auf der Website wiederholen und keine einzigartigen Inhalte angeboten werden? Bei den meisten Menschen führt das zu Frust und Verärgerung. Nutzer:innen verlassen als Reaktion die Website, was wiederum die Bounce-Rate nach oben treibt und das Ranking verschlechtert.
Ursachen für das Auftreten von Duplicate Content
Technische Ursachen
Zu den technischen Ursachen für die Duplizierung von Inhalten gehören u.a. das Vorhandensein von URL-Parametern, Paginierung oder Spiegelungsmechanismen. URL-Parameter erzeugen unterschiedliche URLs für dieselbe Seite. Paginierung tritt auf, wenn Inhalte auf mehrere Seiten verteilt werden, wobei jede Seite eine eigene URL besitzt und somit eine potentielle Dublette darstellt. Spiegelungsmechanismen können z. B. bei der Serverkonfiguration auftreten, wodurch Inhalte unter verschiedenen URLs verfügbar gemacht werden.
Inhaltliche Ursachen
Von Plagiaten spricht man, wenn Inhalte ohne angemessene Quellenangabe oder Genehmigung übernommen werden. Unbeabsichtigte Wiederholungen treten auf, wenn ähnliche oder identische Inhalte auf derselben Website oder auf verschiedenen Websites präsentiert werden. Möchten Sie dieselben Inhalte auf verschiedenen Seiten einer Website präsentieren, sollten Sie Snippets/Schnipsel verwenden.
Infokasten: Syndizierung im Zusammenhang mit Duplicate Content bezieht sich auf die Praxis, Inhalte mit Dritten zu teilen oder zu verbreiten, um sie auf deren Websites zu veröffentlichen. Es kann vorkommen, dass Websitebetreibende Inhalte aus anderen Quellen übernehmen und auf ihren eigenen Websites veröffentlichen, ohne den ursprünglichen Inhalt angemessen zu zitieren oder die Erlaubnis der Urheber:in einzuholen.
Arten von Duplicate Content
Intern Duplicate Content
Interner Duplicate Content bezieht sich auf das Vorhandensein von Duplikaten innerhalb derselben Website oder derselben Domain und kann verschiedene Ursachen haben, z. B. die Verwendung mehrerer URLs für denselben Inhalt, das Vorhandensein von Session-IDs oder die Verwendung von Parametersätzen, die zu unterschiedlichen URLs führen, aber denselben Inhalt anzeigen. Identifizieren Sie rechtzeitig interne Duplikate und ergreifen Sie geeignete Maßnahmen, wie z. B. die Verwendung kanonischer Tags, um Suchmaschinen mitzuteilen, welche Version des Inhalts bevorzugt werden soll, oder die Implementierung von URL-Weiterleitungen, um mehrere URLs auf eine Haupt-URL umzuleiten.
Extern Duplicate Content
Das Vorhandensein von Duplikaten auf verschiedenen Websites oder Domains außerhalb der eigenen Website ist ebenfalls problematisch. Sogenannter externer Duplicate Content hat verschiedene Ursachen, wie z.B. die Syndizierung von Inhalten an verschiedene Dritte, die Übernahme von Inhalten von anderen Websites ohne entsprechende Quellenangabe oder Genehmigung sowie das Auftreten von Plagiaten.
Vermeidungsstrategien für Duplicate Content
Onpage-Optimierungstechniken
Durch die korrekte Implementierung von Canonical Tags, eine optimierte URL-Struktur mit Parameterbereinigung und die Verwendung von Pagination-Tags in Verbindung mit "rel=next" und "rel=prev" lässt sich Duplicate Content vermeiden. Im folgenden erklären wir die einzelnen Maßnahmen:
Canonical Tags: Canonical Tags sind HTML-Link im <head> einer Seite. Diese teilen Suchmaschinen mit, welche Version eines Inhalts als die bevorzugte betrachtet werden soll, sofern es mehrere Versionen gibt. Sie steuern die Indexierung und Gewichtung von Inhalten, indem die richtige Version in den Suchergebnissen angezeigt wird. Das Attribut "rel=canonical" wird in Verbindung mit dem Canonical Tag verwendet, um Suchmaschinen anzuzeigen, welche URL als die kanonische Version betrachtet werden soll.
URL-Struktur und Parameterbereinigung: Die URL-Struktur spielt eine wichtige Rolle bei der Vermeidung von Duplicate Content. Parameterbereinigung bezieht sich auf die Entfernung oder Neutralisierung von URL-Parametern, die den Inhalt nicht verändern, aber verschiedene URLs erzeugen können. Durch die Implementierung einer konsistenten und eindeutigen URL-Struktur sowie die Bereinigung von unnötigen Parametern reduziert sich die Anzahl der Duplikate.
Paginierung: Bei der Darstellung von paginierten Inhalten, wie beispielsweise Seiten mit mehreren Ergebnissen oder Artikelübersichten, ist es wichtig, Suchmaschinen mitzuteilen, wie diese Seiten zusammenhängen. Hier kommen die Attribute "rel=next" und "rel=prev" zum Einsatz. Mit ihnen wird die Reihenfolge und die Verbindung zwischen den Seiten gekennzeichnet. Dadurch erkennen Suchmaschinen paginierte Inhalte als Teil einer Serie.
Technische Ansätze
Durch die Einrichtung einer permanenten Weiterleitung (301 Redirect) von einer URL auf eine andere können Anfragen von Suchmaschinen auf die korrekte Version einer Website umgeleitet werden. Mit einer kleinen Textdatei namens robots.txt kann man Suchmaschinen mitteilen, welche Teile der Website sie indizieren sollen und welche nicht. Gibt es beispielsweise zwei Seiten mit demselben Inhalt, lässt man eine einfach nicht indexieren. In Backend des Sulu CMS funktioniert das über die "no-index"-Option (siehe Screenshot). Robots-Meta-Tags (Link auf https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag?hl=de) sind HTML-Meta-Tags, die Suchmaschinen Anweisungen geben, wie sie eine Webseite indexieren und wie sie mit bestimmten Aspekten umgehen sollen. Durch die korrekte Implementierung von URL-Redirect, effektives URL-Parameter-Handling, die Verwendung von robots.txt und Robots-Meta-Tags kann Duplicate Content vermieden werden.
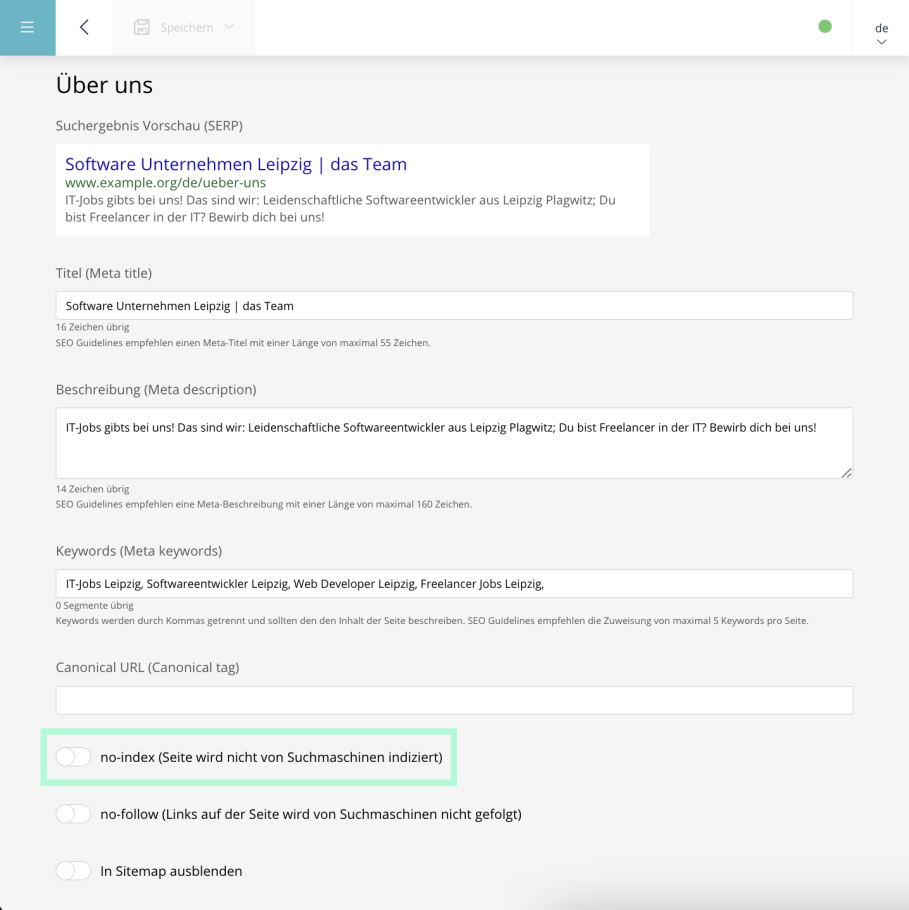
Duplicate Content Check
Sie können Ihre Website manuell auf Duplicate Content überprüfen, indem Sie den Inhalt verschiedener Seiten vergleichen und nach offensichtlichen Duplikaten suchen. Bestimmten Textpassagen oder Inhalte können Sie auf Google oder anderen Suchmaschinen eingeben und schauen, ob diese bereits auf anderen Seiten zu finden sind. Online-Tools wie Copyscape durchsuchen ebenfalls das Internet.
Die Google Search Console bietet Funktionen zur Überwachung und Diagnose von Duplicate Content. Mit dem "HTML-Verbesserungen"-Bericht können Sie Seiten mit potentiellen Duplicate Content-Problemen identifizieren. Wenn Sie ein Content Management System (CMS) wie WordPress verwenden, stehen Ihnen Plugins wie Yoast SEO oder Rank Math zur Verfügung.
Sie interessieren sich für einen SEO-Workshop? Wir bieten individuelle Einzel- und Gruppentrainings an, damit Sie selbstständig SEO-relevante Inhalte für Ihre Website verfassen und veröffentlichen können. Sprechen Sie uns an.